
SIGNAL | AI Valuations Are Polarizing: Capital Is Routing Around the General-Purpose Product Layer

Last week’s Top 10 funding chart doesn’t signal an “AI capital recovery.” It signals a structural repricing: pricing power is migrating rapidly toward both ends of the stack. At one end, foundational model research (seed rounds that mint unicorns on day one). At the other, vertical-workflow companies with entrenched customer lock-in (C/D rounds clearing $100 million per check). In between — horizontal Copilots, general-purpose Agent platforms, horizontal LLM application plays — a collective absence from last week’s Top 10.
This is not a sampling error. SVTR’s AI Deal Database, tracking the past eight weeks of data, shows that among rounds of $100 million or more, the share held by general-purpose AI application companies has fallen from 38% in Q3 2025 to 0% last week. Over the same period, the median valuation for research-stage seed rounds rose 2.4×, and for late-stage vertical Agent rounds, 1.7×.
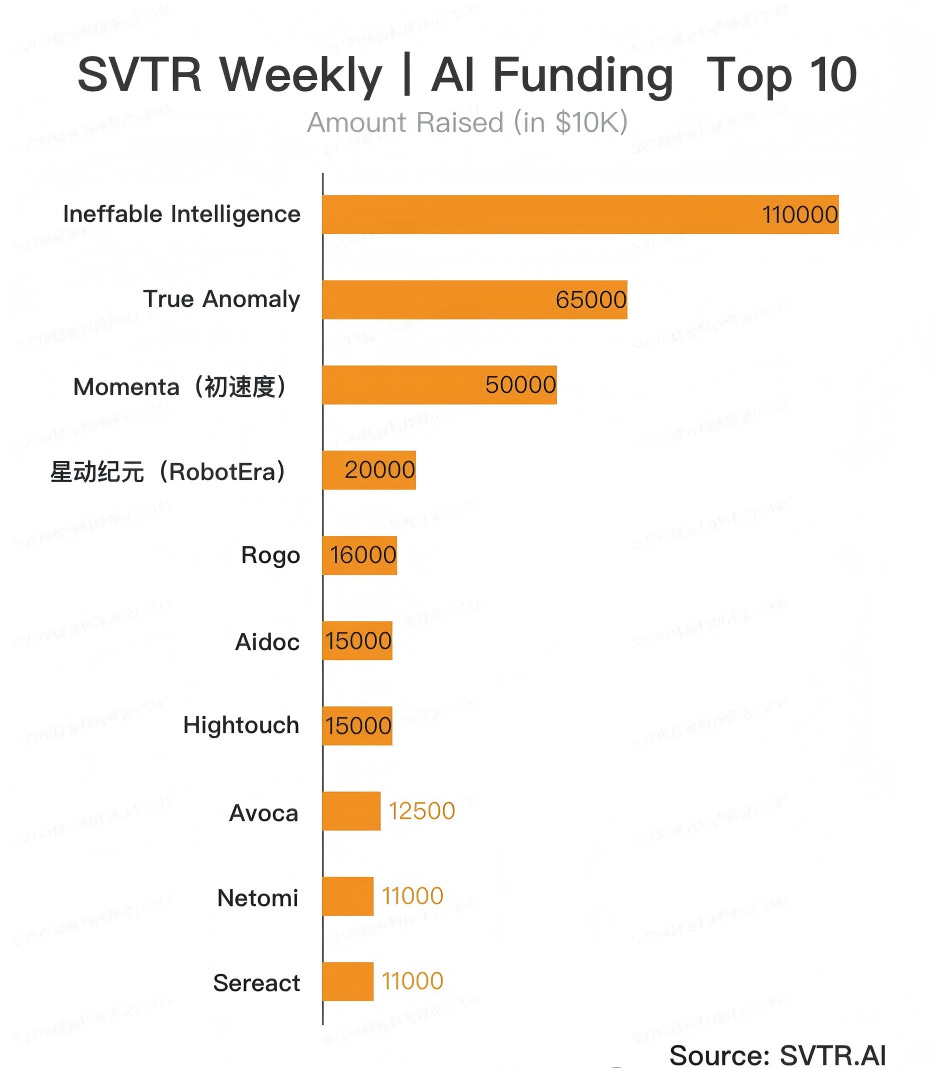
The collapse of the middle layer deserves more attention than the boom at either end. (See chart at the end: Last Week’s Top 10 Funding Rounds.)
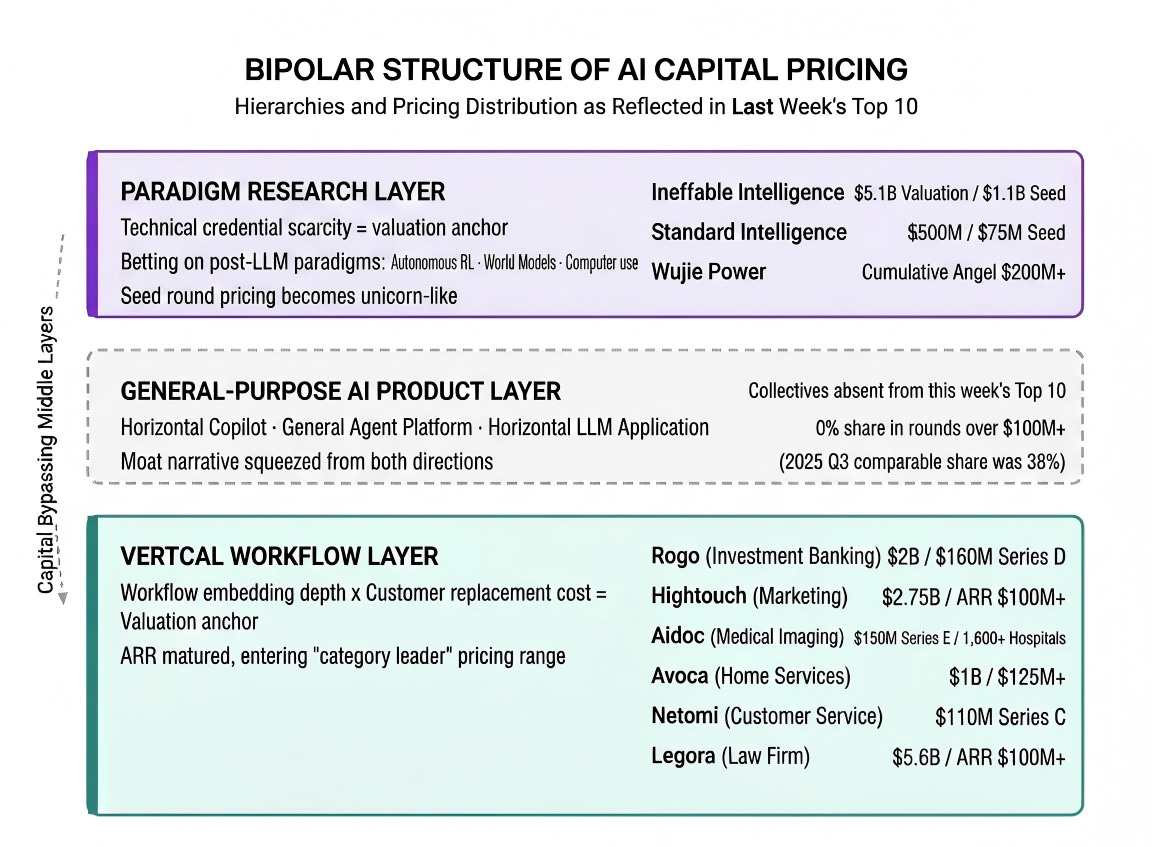
Signal 1 | Seed Rounds Are Being “Unicornified” by Paradigm Research
David Silver’s Ineffable Intelligence redefined what “early-stage betting” means with a single $1.1 billion seed round at a $5.1 billion valuation. Sequoia, Lightspeed, Index, Google, and Nvidia all came in simultaneously — a cap table that looks less like a typical seed syndicate and more like a Series C investor lineup transplanted to day one.
This wasn’t an isolated case. The same week, Standard Intelligence closed a $75 million seed at a $500 million post-money valuation, betting on computer-use models. On the China side, Wujie Power accumulated over $200 million in angel funding on a “native world model + reinforcement learning” thesis. What these three companies share isn’t a sector — it’s a narrative: they’re all betting on “post-LLM paradigms.”
When capital is willing to assign a $5 billion valuation on day one, it means the LP base has already accepted a new premise: the capability curve of general-purpose large language models is converging. The next leap won’t emerge from fine-tuning or RAG — it will require entirely new training paths (autonomous RL, world models, computer use). Once this premise takes hold, the scarcity of “founder credentials” gets rapidly financialized, while the moat narrative for downstream general-purpose application layers gets diluted in reverse.
Signal 2 | Vertical Agents Have Stopped Telling Growth Stories — They’re Telling Category Lock-In Stories
The back half of last week’s Top 10 features a dense cluster of large late-stage rounds forming the other pole: Rogo (investment banking AI / $160M Series D / $2B valuation), Aidoc (medical imaging / $150M Series E / 31 FDA clearances / 1,600+ hospitals), Hightouch (marketing data / $150M / $100M+ ARR / $2.75B valuation), Avoca (home services AI / $125M+ / 800+ enterprise clients), and Netomi (customer service / $110M / clients include Delta and the NBA). Add Legora (legal AI / $50M / $100M+ ARR / $5.6B valuation) from the same week, and that’s at least six companies exhibiting “category leader” characteristics within their respective vertical workflows.
These companies differ from “vertical AI startups” of twelve months ago in two critical dimensions. First, ARR is no longer a $10 million-level story — it’s a $100 million-level reality. Second, the valuation anchor no longer derives from “market size × penetration rate” but from “workflow embedding depth × customer switching cost.” Hightouch’s $2.75 billion valuation against $100M+ ARR implies a 27× multiple — a figure that, in SaaS history, corresponds to companies with established category leadership at Series E/F, not growth-stage companies that just crossed the $100M ARR line.
When capital is willing to pay that multiple, it means these companies are already being priced as the next generation of ServiceNow or Salesforce within “vertical SaaS + AI” — not as one more variant among the sea of general-purpose Copilots.
Signal 3 | The Middle Collapses: General-Purpose AI Products Are Collectively Absent from the Top 10
Zoom out, and not a single company in last week’s Top 10 is a horizontal Copilot, general-purpose Agent platform, or general-purpose LLM application-layer play. The closest candidate to a “middle layer” company might appear to be Parallel Web Systems ($100M Series B / $2B valuation), founded by former Twitter CEO Parag Agrawal — but the product is explicitly positioned as “web search infrastructure for AI agents,” serving downstream Agents as infrastructure rather than being an Agent product itself.
This is a quiet turning point. From 2024 through the first half of 2025, general-purpose Copilots, general-purpose Agent orchestration platforms, and horizontal LLM applications were the most crowded lanes in the AI primary market. Multiple companies secured $1 billion+ valuations at sub-$10M ARR. Last week, the absence of such companies from the Top 10 isn’t a valuation markdown — it’s a complete exit from the frame.
Why is the middle collapsing? Because it’s being squeezed from both directions simultaneously. From above, OpenAI, Anthropic, and Google are embedding general-purpose Agent capabilities directly into their flagship products (ChatGPT, Claude, Gemini), making it nearly impossible for Copilot startups to build moats beyond the model itself. From below, vertical Agent companies have locked in paying enterprise customers through workflow depth, keeping the switching cost of replacing a “general-purpose product” on the procurement list extremely low. When both directions are squeezing, capital simply stops betting on the middle.
Root Cause | Why Now
This repricing is, at its core, a second-order reaction to capability convergence at the LLM model layer.
In 2024, “model capability” itself was still a differentiating variable. General-purpose products could establish temporary leads through prompt engineering, RAG, or fine-tuning. By the second half of 2025, the gap between flagship models on general tasks was narrowing rapidly (GPT-5, Claude Opus 4.7, and Gemini 2.5 shuffle their rankings on standard benchmarks week to week), meaning “model capability delta” can no longer sustain a $1 billion valuation as a moat.
Under this premise, capital can only find genuine differentiation at the two extremes: either bet on the next paradigm (one that doesn’t sit on the LLM convergence curve), or bet on vertical workflows (which don’t compete directly on model capability). The middle layer is on neither the new paradigm nor the workflow-depth axis — so its pricing loses its anchor.
This also explains the tight temporal clustering of all three signals last week: they aren’t independent events, but the same underlying logic surfacing simultaneously across different cross-sections.
Implications | Who Gets Caught in This Repricing
For founders: The fundraising window for general-purpose AI application startups is closing fast. If you’re building a horizontal Copilot, a general-purpose Agent platform, or a prompt-engineering-based LLM application-layer product, you’ll need to make a choice within the next 12 months. Either converge your product depth toward a specific vertical workflow (healthcare, legal, finance, customer service, marketing — pick one), and let ARR, not user counts, do the talking. Or pivot toward a position closer to the model/data/training layer. Products stuck in the middle will struggle to raise their next round on the back of a “fast growth” narrative alone. Over the past 60 days, SVTR’s AI Deal Database shows that 100% of application-layer companies raising rounds of $50 million or more were vertically positioned.
For investors: Valuation frameworks need a rewrite. The old logic of valuing general-purpose AI applications through “DAU × ARPU” or “user growth rates” is breaking down, because these metrics no longer correspond to sustainable moats at the general-purpose layer. The new anchors need to return to two variables: on the vertical axis, “workflow embedding depth” (switching cost, regulatory barriers, data flywheels); on the model axis, “training-paradigm scarcity” (research credentials in RL, world models, computer use, and other non-LLM mainline directions). If a portfolio company has neither accumulated workflow depth nor placed a bet on a new paradigm, its valuation anchor needs to be proactively adjusted downward.
For Big Tech: OpenAI, Anthropic, and Google’s “product-layer squeeze” strategy was indirectly validated by last week’s capital flows. Their incentive to keep squeezing upward at the general-purpose layer will only strengthen.
For enterprise buyers: On procurement lists, the budget split between “general-purpose Copilots” and “vertical workflow Agents” will continue to diverge. The former increasingly folds into Big Tech subscriptions; the latter becomes a standalone line item.
Validation | Three Key Metrics Worth Tracking
Over the next 90 days, these three metrics can validate whether this signal holds:
Median seed valuation for general-purpose AI application-layer companies. Watch whether the median seed valuation for horizontal Copilots and general-purpose Agent platforms in Q1 2026 has declined 30%+ from Q3 2025. If so, the repricing thesis is confirmed.
Number of vertical AI companies entering the $2B+ valuation tier. Watch whether, within 90 days, three or more vertical AI companies with ARR above $50M enter the $2B+ valuation zone. If so, the category lock-in logic is being consistently priced in.
Whether a second “seed-round unicorn” appears. Watch whether another company with RL, world model, or computer-use research credentials emerges at a $500M+ seed valuation. If two or more appear, “academic-founder unicornification” has become a structural phenomenon rather than an outlier.
If all three metrics are confirmed within 90 days, last week’s Top 10 reflects not a weekly fluctuation, but the starting point of the 2026 AI primary market pricing framework.
SVTR’s AI Deal Database has completed retroactive tagging across three categories — “model research layer / general-purpose product layer / vertical workflow layer.” It can now filter comparable historical rounds and valuation multiples across the six verticals featured in last week’s Top 10 (investment banking, medical imaging, marketing, home services, customer service, legal) over the past 72 months, providing a reference map for founders and investors recalibrating their pricing frameworks this quarter.